BERT(Bidirectional Encoder Representations from Transformers)是一种基于Transformer架构的双向语言表示模型,由Google在2018年发布。它通过在所有层中对左右上下文进行联合条件反射,从未标记的文本中预训练深度双向表示。BERT的创新之处在于借助Transformer学习双向表示,不同于递归神经网络(RNN)对顺序的依赖性,它能够并行处理整个序列,从而可以分析规模更大的数据集,并加快模型训练速度。
BERT的核心原理是在海量文本中学习词汇的双向上下文。它采用了Mask Language Model (MLM) 和 Next Sentence Prediction (NSP) 两种预训练任务。MLM让BERT猜测被遮住的词,而NSP则帮助理解句子之间的关系。通过这种方式,BERT具备了惊人的语义理解能力。BERT的输入是一个原始的文本序列,它可以是单个句子,也可以是两个句子(例如,问答任务中的问题和答案)。在输入到模型之前,这些文本需要经过特定的预处理步骤。
BERT的网络结构由多个Transformer编码器层堆叠而成。每个编码器层都包含自注意力机制和前馈神经网络,允许模型捕捉输入序列中的复杂依赖关系。自注意力机制允许模型在处理序列时关注不同位置的Token,并计算Token之间的注意力权重,从而捕捉输入序列中的依赖关系。BERT的输出取决于特定的任务。在预训练阶段,BERT采用了两种任务:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。
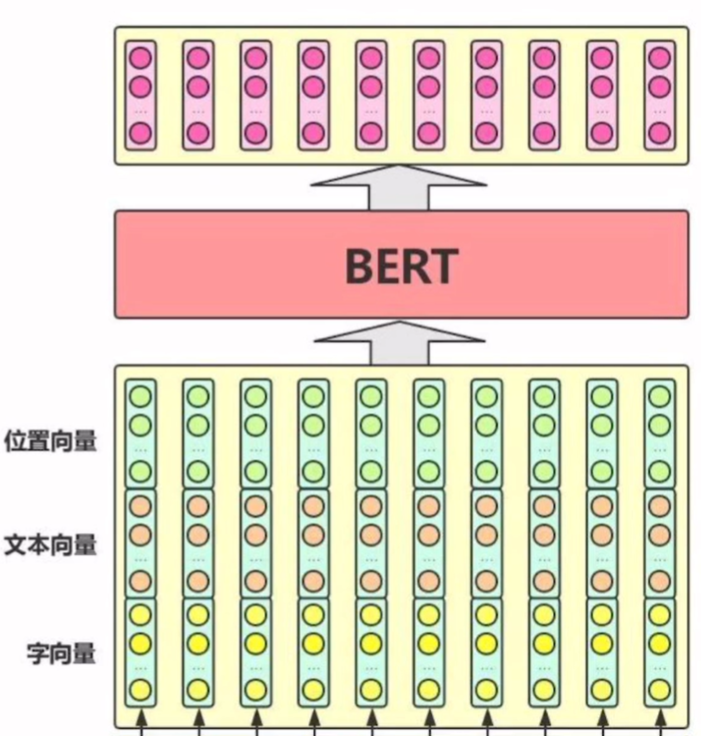
BERT模型的输入通过结合Token Embeddings、Segment Embeddings和Position Embeddings三种嵌入方式,能够全面捕获文本的语义和上下文信息,为各类自然语言处理任务提供强大的基础表示能力。BERT的工作原理是通过在大规模未标注数据上执行预训练任务(如Masked Language Model来捕获文本中词汇的双向上下文关系,以及Next Sentence Prediction来理解句子间的逻辑关系),再将预训练的模型针对特定任务进行Fine tuning,从而在各种自然语言处理任务中实现高性能。
总览了解:
step_1: pre_training [预训练]
MLM: Master Language Model 通俗地理解就是,在输入一句话时,随机地选择要预测的词,用特殊符号mask来遮掩代替,之后让模型根据标签学习预测
NSP: Next Sentence Prediction 在双向语言模型的基础上额外增加了一个句子级别的连续型预测任务,更好地让模型学习到连续片段之间地关系