堆利用
堆利用
目前堆的实现有很多种,具体如下
1 | |
part_1
学习文章:【Linux 内核源码分析】堆内存管理-CSDN博客
堆
堆是一种动态分配内存的数据结构,用于存储和管理动态分配的对象。它是一块连续的内存空间,用于存储程序运行时动态申请的内存。
堆可以被看作是一个由各个内存块组成的堆栈,其中每个内存块都有一个地址指针,指向下一个内存块。当程序需要分配内存时,堆会根据分配算法找到一块足够大的连续内存空间,并将其分配给程序。程序可以在堆中动态创建和销毁对象,而不需要在编译时确定对象的数量或大小。
与静态分配的栈不同,堆的内存分配不是自动的,需要显式地通过内存分配函数(如malloc、new等)来申请内存空间,并在不使用时通过释放函数(如free、delete等)来释放已分配的内存。这种动态的内存管理方式使得程序能够根据实际需要来动态调整内存的使用情况。
堆内存管理
在Linux操作系统中,堆内存是指用于动态分配的一块内存区域。它与程序的堆栈(stack)不同,堆内存是由程序员通过函数如malloc()、calloc()或realloc()等来手动申请和释放的。
堆内存的特点:
- 大小可变:堆内存的大小可以在运行时动态地调整,适应不同需求。
- 手动管理:开发人员需要手动申请和释放堆内存,并且负责确保正确使用和及时释放,以避免内存泄漏或悬挂指针等问题。
- 随机访问:程序可以随机访问堆内存中的数据。
- 生命周期长:除非显式释放或程序结束,否则分配给堆内存的空间会一直存在
堆内存是连续分配的内存,在大多数操作系统中,包括Linux,堆内存是通过动态分配内存来管理的。它通常是一个连续的内存区域,用于动态分配和释放内存块。
堆内存的生长方向是自下而上:在传统的内存布局中,堆内存的生长方向是从低地址向高地址增长。这意味着每次分配新的内存块时,堆会从较低的地址向上移动。
堆内存的管理由 Linux 内核实现:Linux 内核提供了一些系统调用和函数,用于管理堆内存。这些系统调用和函数使开发者能够请求分配和释放堆内存,但开发者并不直接知道堆的管理细节。
系统调用用于调用相关函数:开发者可以使用系统调用来请求堆内存的扩展和收缩。其中一个常用的系统调用是 brk,它负责调整程序的堆边界,以便在需要时扩展或收缩堆内存。
在 Linux 内核中,mm_struct 结构体表示进程的内存管理信息,其中包含了堆的起始地址和结束地址:
start_brk表示堆内存在虚拟地址空间中的起始地址,通常是初始的堆边界。brk表示堆内存在虚拟地址空间中的结束地址,即当前的堆边界。
start_brk 和 brk 之间的地址空间就是堆内存的大小。在进程运行过程中,可以通过相应的系统调用(如 brk 或 sbrk)来动态扩展或收缩堆内存的大小,从而改变堆边界的位置。
需要注意的是,mm_struct 结构体中还包含了其他与内存管理相关的信息,如代码段、数据段、栈等的起始地址和结束地址。这些信息共同构成了进程的虚拟地址空间,用于进行内存管理和保护。
Slab 是一种基于对象缓存的内存分配器。它将内核对象按照类型进行分类,并为每种类型分配一个独立的缓存池,缓存池中包含了若干个连续的 Slab 对象,当内核对象需要分配内存时,Slab 分配器会从相应的缓存池中申请一个 Slab 对象,并将其划分为多个小块以供程序使用。当程序释放内存时,Slab 分配器会将该内存块标记为空闲状态,并加入到 Slab 缓存池中以供后续的内存分配使用。Slab 分配器通过对象缓存机制,可以提高内存分配效率和内存利用率,并减少内存碎片的产生。
SLOB(Simple List Of Blocks)是一种基于 Free 链表的简单内存分配器。它通过维护一个链表来记录空闲块的位置和大小,当程序需要分配内存时,SLOB 分配器会在 Free 链表中查找一个大小合适的空闲块,并将该块分配给程序。当程序释放内存时,SLOB 分配器会将该内存块加入到 Free 链表中,以供后续的内存分配使用。SLOB 分配器由于实现简单,因此可以在内核体积和性能之间进行权衡。
内存描述mm_struct结构体
在 Linux 内核源码的 include/linux/mm_types.h 文件中包含了 mm_struct 结构体的定义。
1 | |
mm_struct 结构体中的 start_brk、brk 成员
在 mm_struct 结构体中,start_brk 和 brk 是与进程的堆内存相关的成员变量。
start_brk 表示进程堆的起始地址。
brk 表示进程堆的结束地址。
虚拟地址空间是一个抽象的概念,用于表示进程可用的地址范围。它将进程的内存分为多个区域,包括代码段、数据段、堆、栈等。堆是其中的一个区域,用于动态分配内存。
start_brk 是堆内存的起始地址,表示堆的开始位置。在该地址之前的内存区域属于其他区域(如数据段),而在该地址之后的内存区域则属于堆。
brk 是堆内存的结束地址,表示堆的结束位置。堆的所有分配的内存都位于 start_brk 和 brk 之间。
通过控制 brk 的值,可以动态调整堆内存的大小。当需要分配更多的堆内存时,可以通过增加 brk 的值来扩展堆,使其占用更多的虚拟地址空间。相反,当释放不再需要的堆内存时,可以通过减小 brk 的值来缩小堆的大小,从而释放占用的虚拟地址空间。
在 Linux 内核源码的 include/linux/mm_types.h 文件中,包含了 start_brk 和 brk 成员的定义。
1 | |
动态分配内存堆
在 Linux 系统中,有两种常见的方式用于动态分配堆内存:
1.brk() 和 sbrk():这是最基本和最原始的动态内存分配方式。brk() 函数用于将进程的堆结束地址设置为指定的值,从而控制堆内存的大小。sbrk() 函数则通过增加进程的堆结束地址来分配内存,通过减小堆结束地址来释放内存。这些函数存在于 POSIX 标准中,是 C 语言标准库中的一部分。
2.malloc() 和 free():这是更高级的动态内存分配方式。malloc() 函数用于在堆内存中分配指定大小的内存块,并返回指向该内存块的指针。free() 函数用于释放先前分配的内存块。这些函数在 C 标准库中实现,通常会比 brk() 和 sbrk() 更易于使用和管理。
这两种动态内存分配方式各有优点和缺点。brk() 和 sbrk() 的优势在于它们非常简单且直接,可以轻松地控制堆内存的大小。但是,它们的缺点是需要手动管理内存,并且容易出现内存泄漏和其他问题。malloc() 和 free() 则提供了更高级的内存管理功能,使得内存分配和释放更容易且更安全。但是,它们的实现可能会比较复杂,可能需要使用锁和其他机制来确保多线程环境下的正确性。
brk系统调用
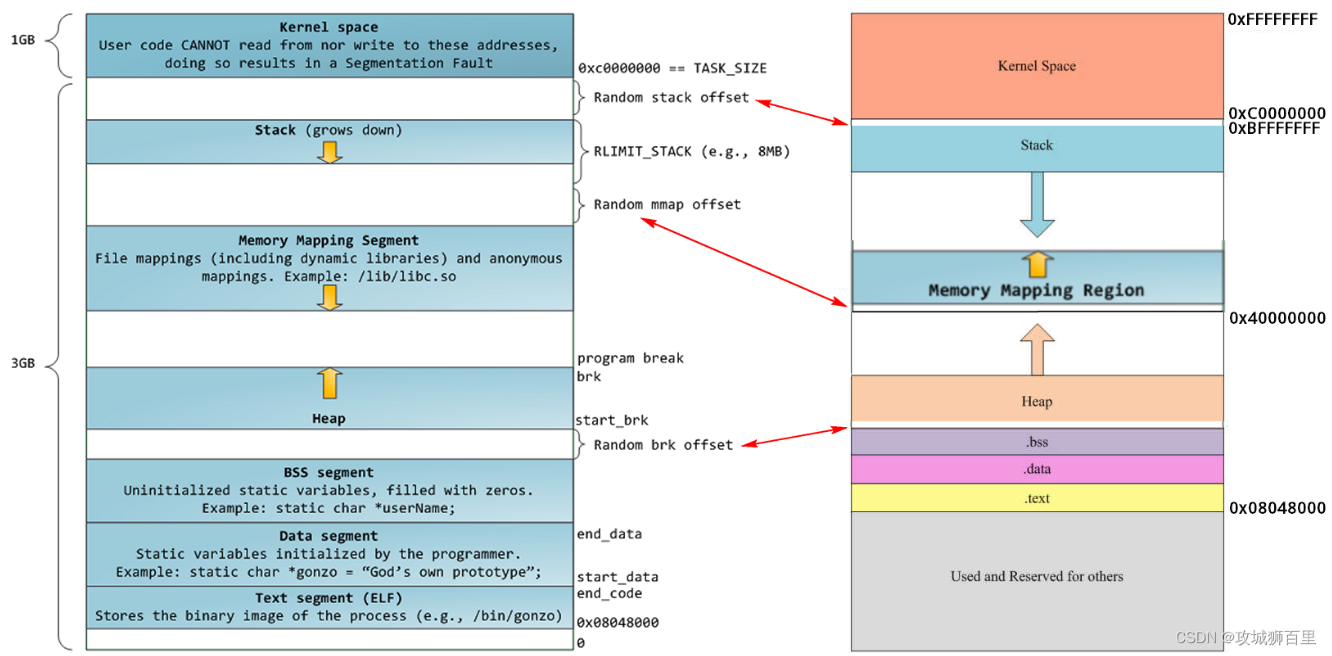
在Linux内核源码中的mm/mmap.c文件中,可以找到brk系统调用的定义。
1 | |
通过使用brk系统调用,可以指定堆内存在虚拟内存空间的结束地址。
当需要扩展堆内存时,可以将结束地址设置为大于当前值。这样,系统会增加虚拟内存空间以容纳更多的堆内存,并将新的结束地址返回给调用者。
而当需要收缩堆内存时,可以将结束地址设置为小于当前值。这样,系统会释放超过该结束地址的部分虚拟内存空间,使其可供其他用途使用。
mmap系统调用
mmap系统调用的相关代码可以在Linux内核源码的mm/mmap.c文件中找到。
1 | |
mmap 系统调用执行成功时,返回映射区域的起始地址,该地址与请求的 addr 可能会有所不同(如果 addr 是 NULL,则由操作系统自动分配合适的地址)。如果发生错误,mmap 返回 MAP_FAILED。
heap_info
在 Linux 中,堆管理是通过内核提供的系统调用和库函数来实现的。其中,glibc 库是 Linux 上最常用的 C 语言库之一,它提供了一组用于堆管理的函数,如 malloc、free、calloc、realloc 等。
在 glibc 中,堆是由多个内存块组成的链表,每个内存块都有一个 heap_info 结构体来描述它所在的堆。heap_info 结构体定义在 glibc 的 malloc/malloc.c 文件中,它包含以下字段:
1 | |
通过遍历 heap_info 结构体链表,程序可以获取当前进程所有的堆信息,并对其进行操作和监控。
1 | |
malloc_state
malloc_state 可以看作是堆管理中的 Arena Header,它维护了当前线程所属的堆内存的状态。每个线程只包含一个 malloc_state 结构体,用于管理该线程所使用的堆内存。在多线程环境下,不同线程的 malloc_state 结构体相互独立,互不干扰。
1 | |